
In the world of data engineering and database management, optimizing query performance is paramount to ensuring efficient and responsive systems. As a lead data engineer, you understand the criticality of addressing issues related to poor API response times and sluggish ETL pipelines. One powerful technique that can significantly improve MySQL query performance is “MySQL partitioning.” In this comprehensive guide, we will explore the key benefits and techniques of MySQL partitioning, enabling you to unleash the true potential of your database.
Table of Contents
Setup
I am using a local MySQL server, MySQL workbench, and salaries table from the sample employee data. You can also download the dumps of the salaries table’s sample data from here.
Understanding MySQL Partitioning
MySQL is a Relational Database Management System (RDBMS) which stores data in the form of rows and columns in a table.
Different DB engine stores table data in the file systems in such a way, if you run a simple filter query on a table it will scan the whole file in which table data is stored.
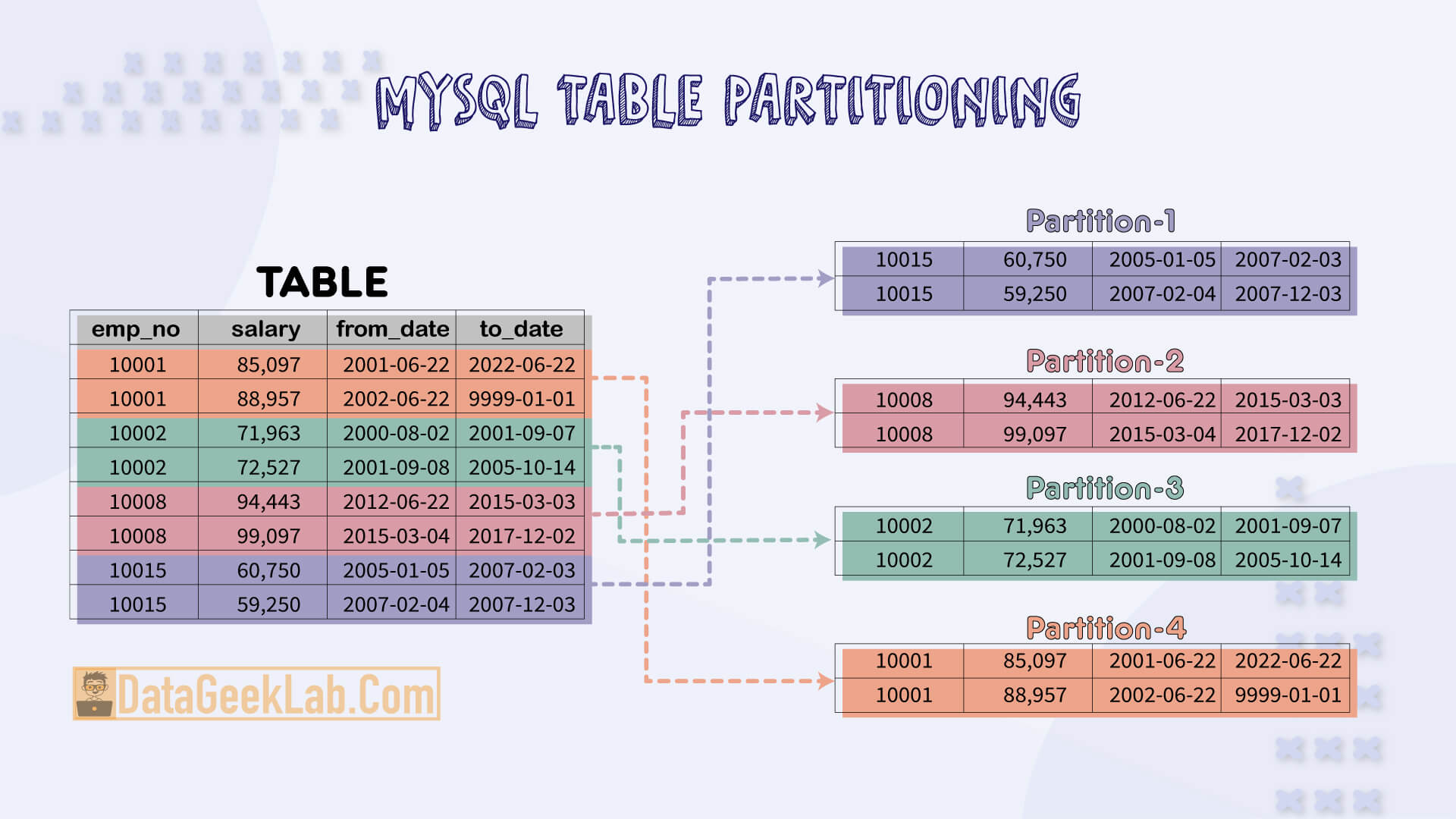
Partitioning a table divides the data into logical chunks based on keys(columns values) and stores the chunks inside the file system in such a way, if a simple filter query is run on the partitioned table it will only scan the file containing a chunk of data that you required.
So in a way partitioning distributes your table’s data across the file system, so when the query is run on a table only a fraction of data is processed which results in better performance.
Lets take an example :
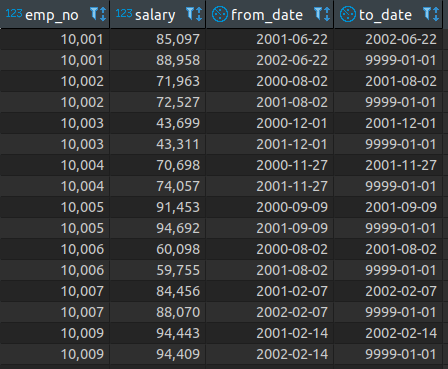
Data in our salaries table looks like this:
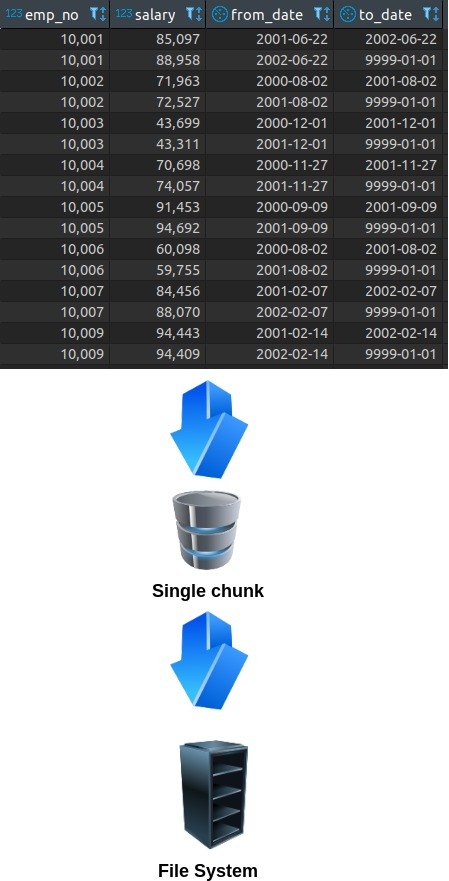
By default, this data is stored in a single chunk inside the file system.
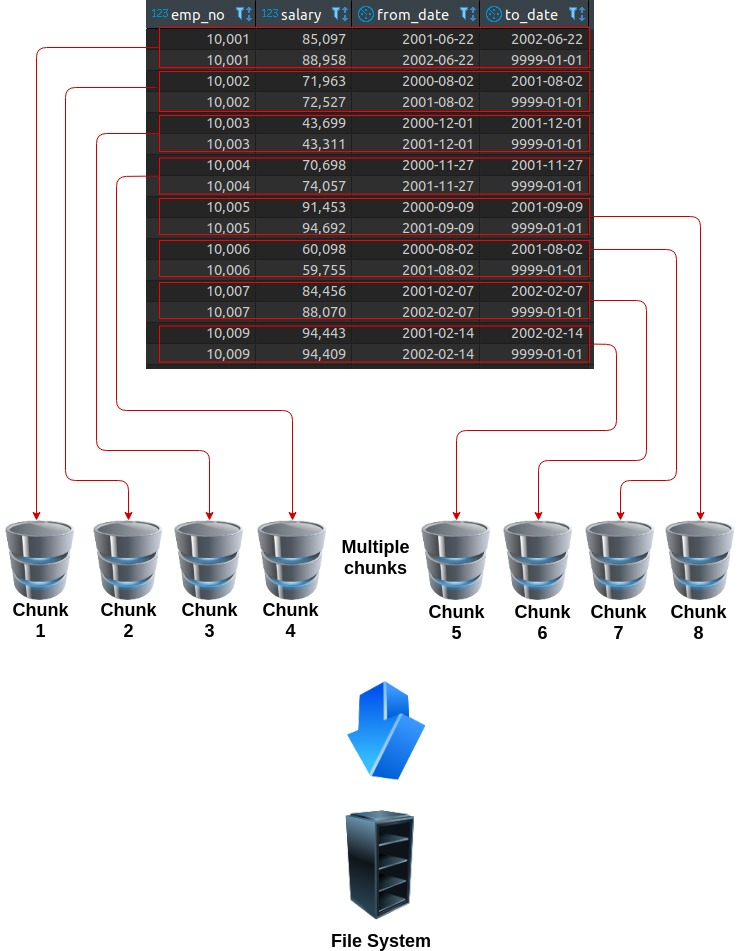
If we partition the table by taking “emp_no” columns as key the data will be stored in multiple chunks based on number of partitions:
Now we understand how partitioning works let us see different partitioning types in MySQL.
Partitioning Techniques in MySQL
1. Range Partitioning
Range partitioning involves dividing data based on a specified range of column values. For example, you can partition a table based on date ranges, such as monthly or yearly intervals. This technique is beneficial for time-series data or any data with a natural ordering. Sample query is given below:
CREATE TABLE sales (
sale_id INT AUTO_INCREMENT PRIMARY KEY,
sale_date DATE,
product_name VARCHAR(255),
sale_amount DECIMAL(10, 2)
)
PARTITION BY RANGE (YEAR(sale_date)) (
PARTITION p0 VALUES LESS THAN (2022),
PARTITION p1 VALUES LESS THAN (2023),
PARTITION p2 VALUES LESS THAN (2024)
);2. List Partitioning
List partitioning involves dividing data based on specific values in a designated column. This technique is useful when you have discrete categories or classes of data. Sample query is given below:
CREATE TABLE customer_data (
customer_id INT AUTO_INCREMENT PRIMARY KEY,
customer_name VARCHAR(255),
customer_category VARCHAR(50),
customer_age INT
)
PARTITION BY LIST (customer_category) (
PARTITION p_golden_customers VALUES IN ('Gold', 'Platinum'),
PARTITION p_silver_customers VALUES IN ('Silver', 'Bronze'),
PARTITION p_regular_customers VALUES IN ('Regular')
);
3. Hash Partitioning
Hash partitioning involves distributing data across partitions based on the result of a hashing function applied to a specific column. This technique ensures a relatively even distribution of data, making it suitable for scenarios with unpredictable data distribution. Sample query is given below:If you are in the market for superclone Replica Rolex , Super Clone Rolex is the place to go! The largest collection of fake Rolex watches online!
CREATE TABLE sensor_data (
sensor_id INT AUTO_INCREMENT PRIMARY KEY,
reading_timestamp TIMESTAMP,
sensor_value FLOAT
)
PARTITION BY HASH (sensor_id)
PARTITIONS 4;
Implementing MySQL Partitioning
Before you implement partitioning in your MySQL database, ensure that the following prerequisites are met:
1. Use the InnoDB Storage Engine: Partitioning is supported by the InnoDB storage engine. If your table is not already using InnoDB, convert it using the following query:
ALTER TABLE your_table ENGINE = InnoDB;2. Identify the Partitioning Key: Choose a column or a set of columns as the partitioning key, based on the nature of your data and the desired query optimisation.
3. Define the Partitioning Scheme: Select an appropriate partitioning technique (range, list, or hash) that aligns with your data distribution and access patterns.
4. Consider Performance and Maintenance: While partitioning enhances performance, it also introduces maintenance tasks like managing partitions and optimizing queries. Evaluate the trade-offs to ensure that partitioning aligns with your performance goals.
NOTE: For existing tables, you can add partitions using the ALTER TABLE statement. For example, to add a new partition to an existing range-partitioned table:
ALTER TABLE your_table
ADD PARTITION (
PARTITION new_partition VALUES LESS THAN (2025)
);
Demo
Now let us get back to our sample “salaries” table for demo. We will use the below simple query for testing:
SELECT * FROM salaries WHERE emp_no='10001' AND from_date> '1995–06–01';I have run this query multiple times as shown below, and the average run time is 1.7302 sec approx.
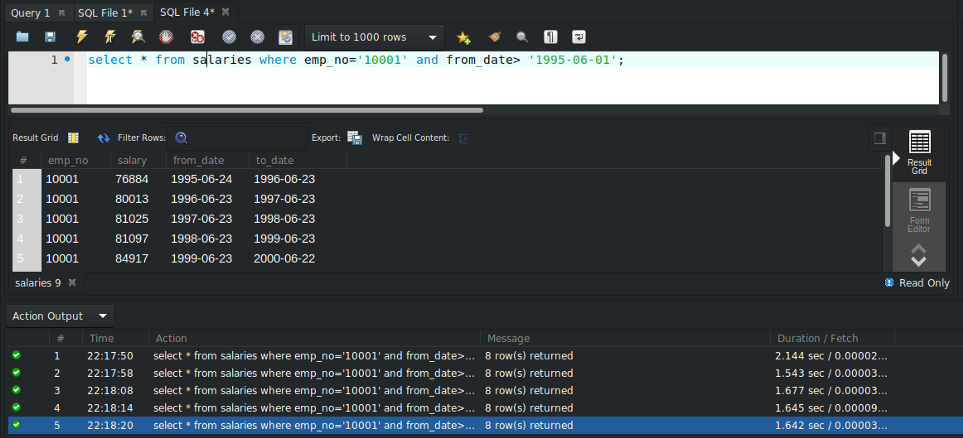
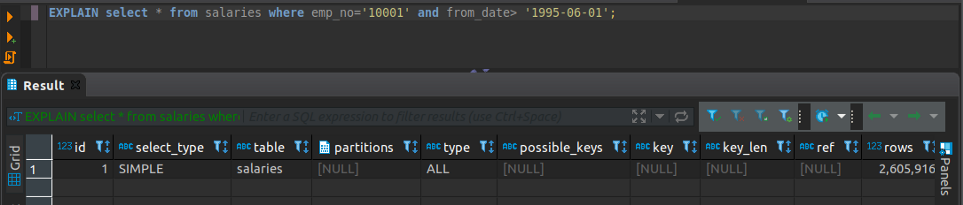
Let us examine how MySQL executes this query using EXPLAIN clause.
EXPLAIN SELECT * FROM salaries WHERE emp_no='10001' AND from_date> '1995–06–01';As we can see from the result there are no partitions in this table that is why the “partitions” column has a NULL value.
Let create another table with the same schema.
CREATE TABLE test_salaries LIKE salaries;Now we will create partitions on this table before inserting data.
ALTER TABLE test_salaries PARTITION BY KEY(emp_no) PARTITIONS 100;I am selecting “emp_no” column as a key, in production you should carefully select this key column for better performance, use the guide specified above.
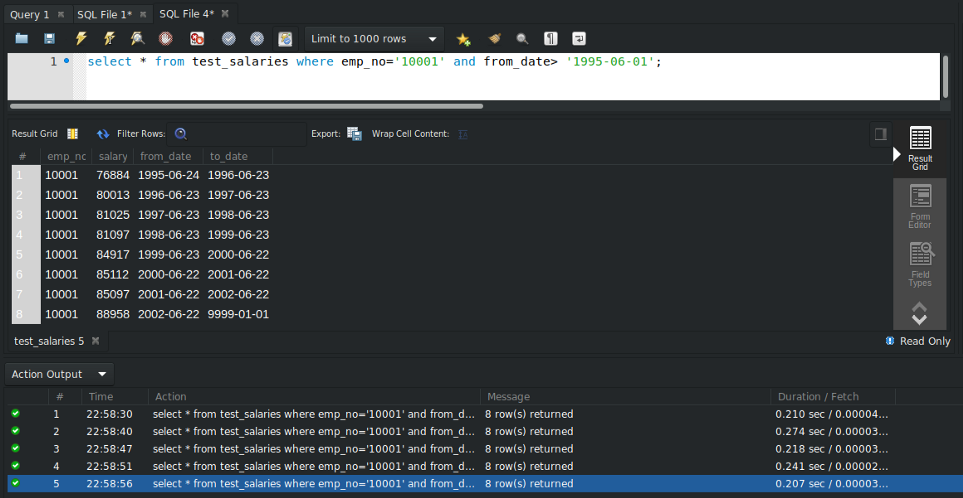
Again I ran this query multiple times as shown above, and the average run time is 0.23 sec approx.
So as we can see there is a significant improvement of the query run time from 1.7302 sec to 0.23 sec.
Once again let’s check how MySQL executes this query in the partitioned table by using EXPLAIN clause.
EXPLAIN SELECT * FROM test_salaries WHERE emp_no=’10001' AND from_date> ‘1995–06–01’;
This time partitions column returns some value in my case it’s p73(Might be different for you).
So what’s actually happening is that MySQL is scanning only one partition (a small chunk of data) which is why the query runs significantly faster than the non-partitioned table.
Key Benefits of MySQL Partitioning
- Enhanced Query Performance: By dividing large tables into smaller partitions, MySQL can focus on processing only the relevant data during query execution. This dramatically reduces the amount of data scanned, leading to faster and more responsive queries.
- Improved Data Management: Partitioning enables better data management as each partition can be backed up, restored, or modified independently. This flexibility makes tasks like archiving historical data or managing frequently updated data subsets much more streamlined.
- Efficient Indexing: With partitioning, you can create indexes on specific partitions, allowing for faster index scans and reduced index maintenance overhead.
- Seamless Data Purging: Managing data retention and purging becomes more straightforward with partitioning. By dropping or archiving entire partitions, you can efficiently remove outdated or unnecessary data from your database.
- High Availability and Scalability: Partitioning can improve database performance, especially in high-traffic scenarios, and allows for horizontal scaling, enabling your system to handle increasing data volumes without sacrificing responsiveness.
Conclusion
MySQL partitioning is a powerful technique that can significantly boost query performance and streamline data management in large databases. By strategically organising data into smaller, manageable partitions, you can unlock the full potential of your MySQL database, resulting in faster and more efficient query processing. Remember to choose the right partitioning technique based on your data characteristics and access patterns, and always balance performance gains with maintenance overhead.
With the knowledge gained from this guide, you are now equipped to harness the benefits of MySQL partitioning and optimise your database for high-performance data operations. Implement partitioning in your MySQL ecosystem and experience the transformative impact it can have on your data-driven applications.
I’m not sure where you are getting your info, but good topic. I needs to spend some time learning more or understanding more. Thanks for wonderful information I was looking for this information for my mission.
Everyone loves what you guys are up too. Such clever work and coverage!
Keep up the good works guys I’ve you guys to our blogroll.