
In today’s data-driven world, efficient management and orchestration of data workflows are essential for organizations to extract insights and drive decision-making. Apache Airflow, an open-source platform, has emerged as a popular choice among data engineers for its powerful capabilities in automating and monitoring workflows. In this comprehensive Apache Airflow Architecture Tutorial, we will explore the various components of Airflow that make it a versatile tool for streamlining data workflows, and delve deeper into their functionalities.
Airflow’s core strength lies in its ability to define, schedule, and monitor workflows through Directed Acyclic Graphs (DAGs). DAGs provide a visual representation of tasks and their dependencies, allowing for flexible and scalable workflow design. Developers write DAGs as Python scripts, leveraging Airflow’s extensive library of operators and connections. The power of Airflow’s DAGs lies in their expressiveness and the ability to handle complex workflows with ease.
In this article, we will see the different components of Airflow and their relationship
Section 1: Developer and DAG Files
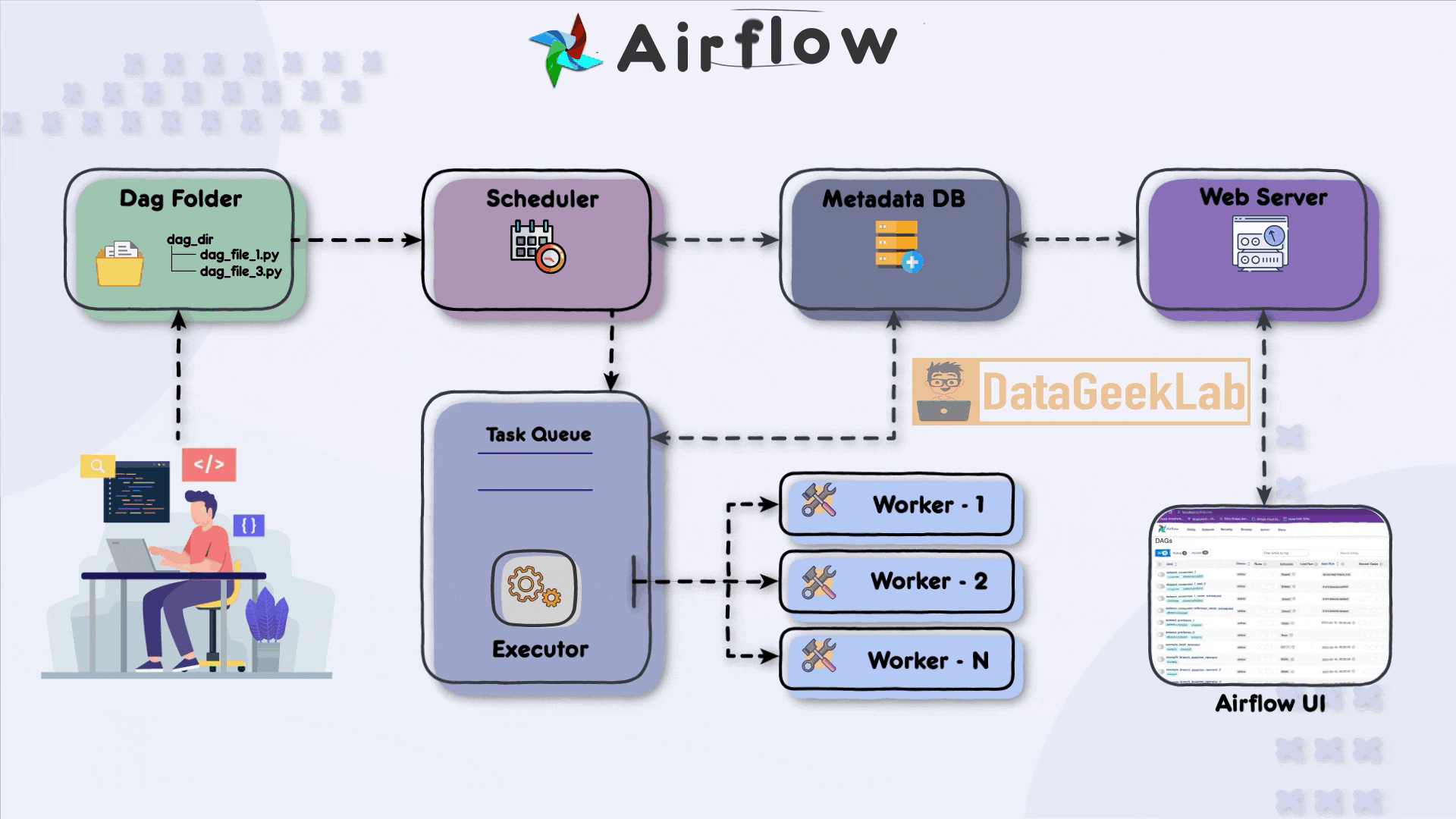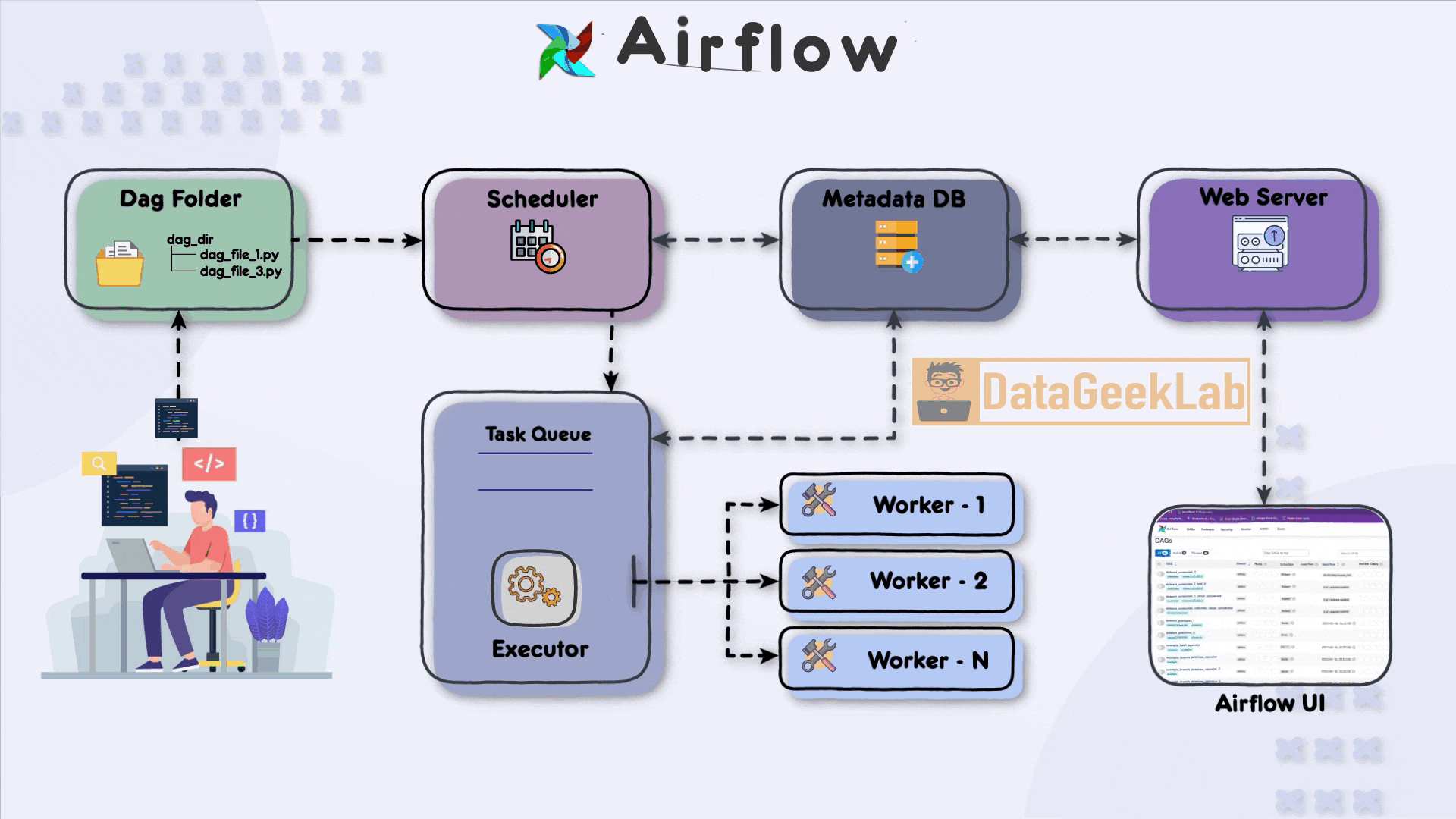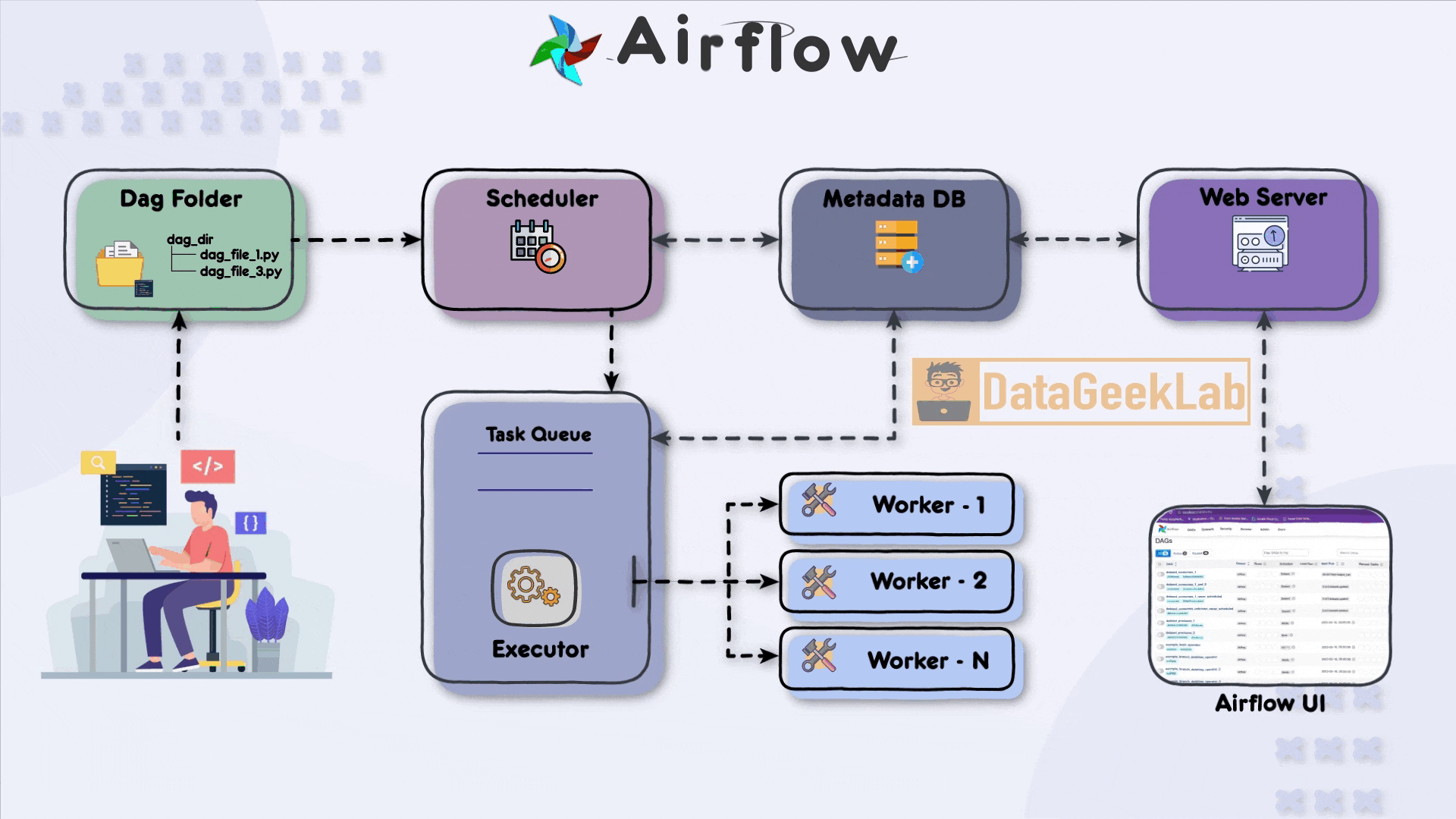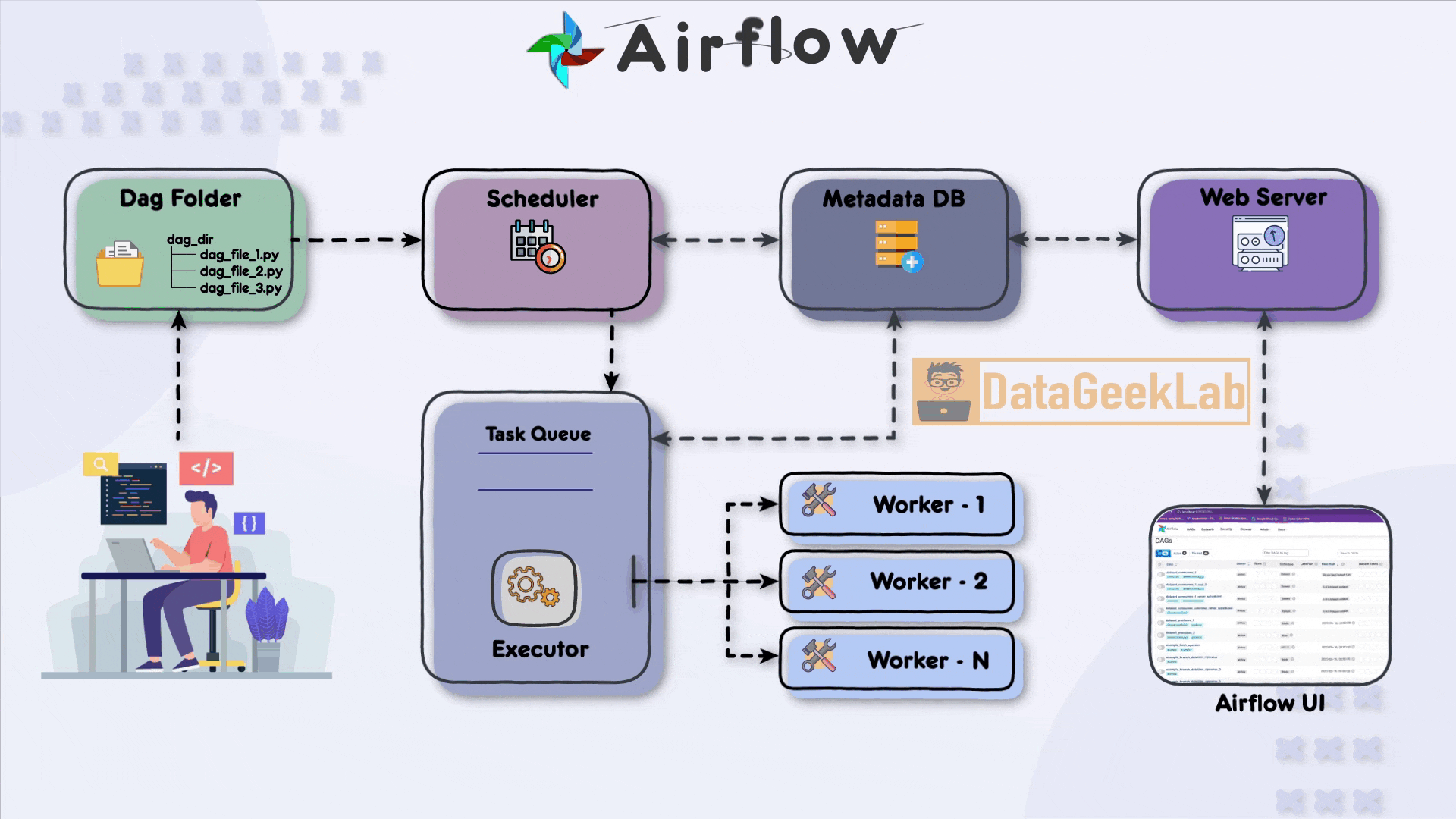
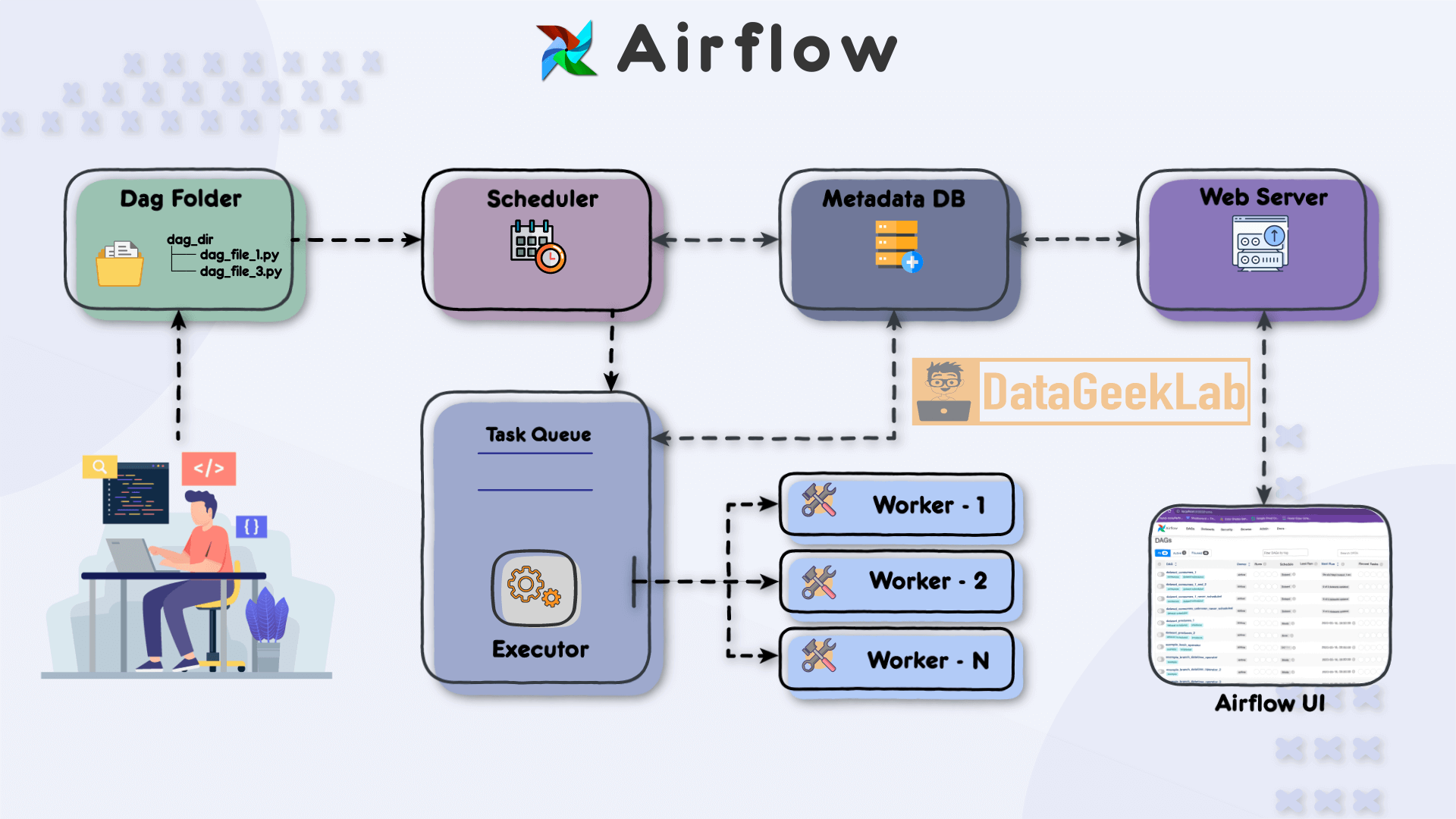
The first step in leveraging Airflow is for the developer to write a Directed Acyclic Graph (DAG) file using Python. The DAG file defines the workflow and the tasks that need to be executed. It allows the developer to specify the order in which tasks should run and define their dependencies. Once the DAG file is ready, it is placed in a designated folder known as the “DAG folder”, this is the first component of Apache Airflow Architecture, which serves as the central location for Airflow to monitor and identify changes in the workflows.
Below is a sample DAG file for understanding first component of Apache Airflow Architecture:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime
# Define the DAG
dag = DAG(
'sample_dag',
description='A sample DAG for data workflow',
schedule_interval='0 0 * * *', # Runs once daily at midnight
start_date=datetime(2023, 6, 1),
catchup=False
)
# Define the tasks
task1 = BashOperator(
task_id='task1',
bash_command='echo "Executing Task 1"',
dag=dag
)
task2 = BashOperator(
task_id='task2',
bash_command='echo "Executing Task 2"',
dag=dag
)
task3 = BashOperator(
task_id='task3',
bash_command='echo "Executing Task 3"',
dag=dag
)
# Define the task dependencies
task1 >> task2 >> task3In this sample DAG, we import the necessary modules from Airflow and define the DAG with a unique ID, description, schedule interval, start date, and catch-up option. The DAG is scheduled to run once daily at midnight, starting from June 1, 2023, without catching up on any missed runs.
Next, we define three tasks using the BashOperator which allows us to execute bash commands. Each task has a unique task ID, a bash command to be executed, and is associated with the DAG.
Finally, we define the task dependencies using the >> operator. In this example, task1 must complete before task2 can start, and task2 must complete before task3 can start.
Section 2: Scheduler and Task Queue
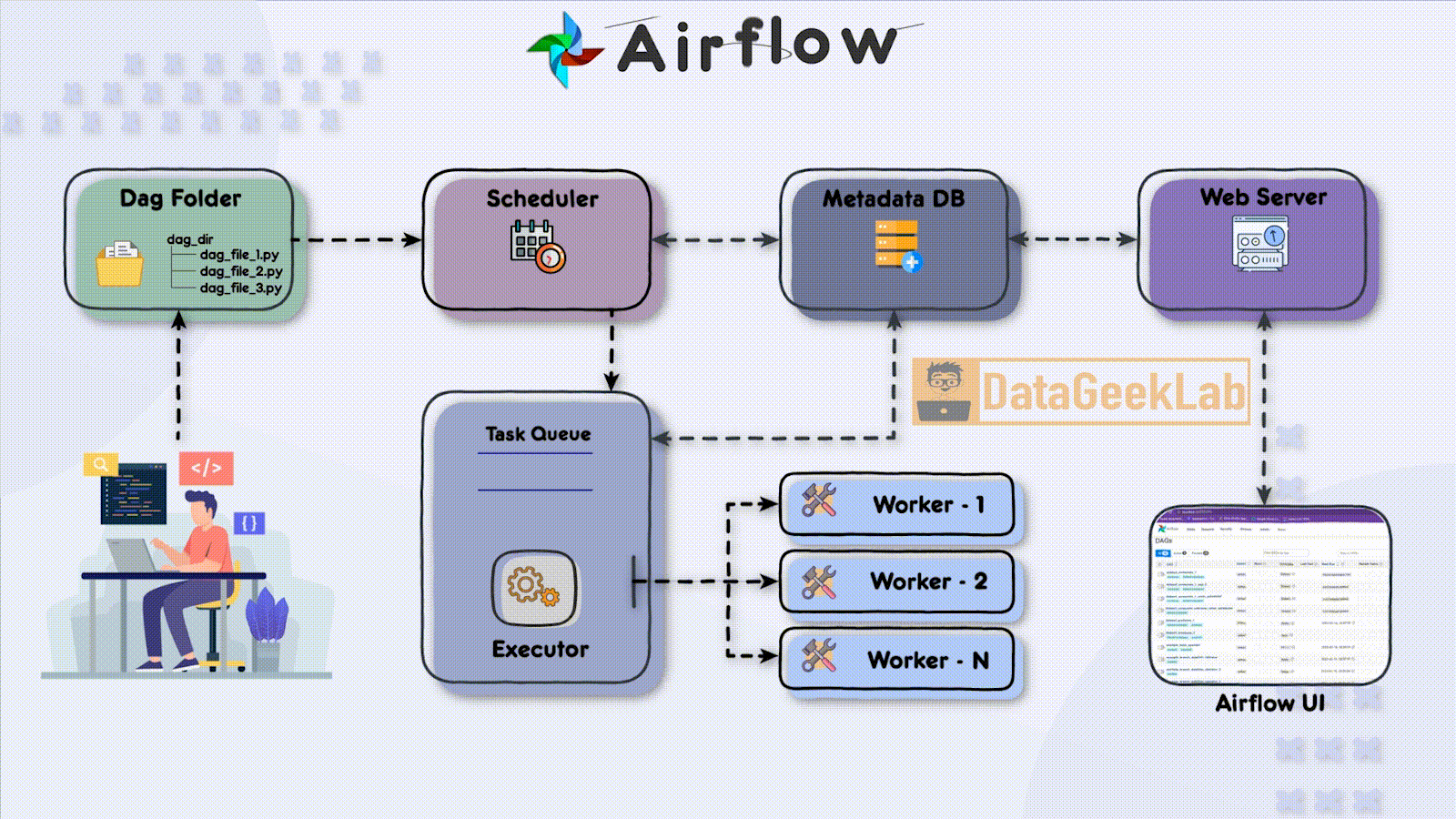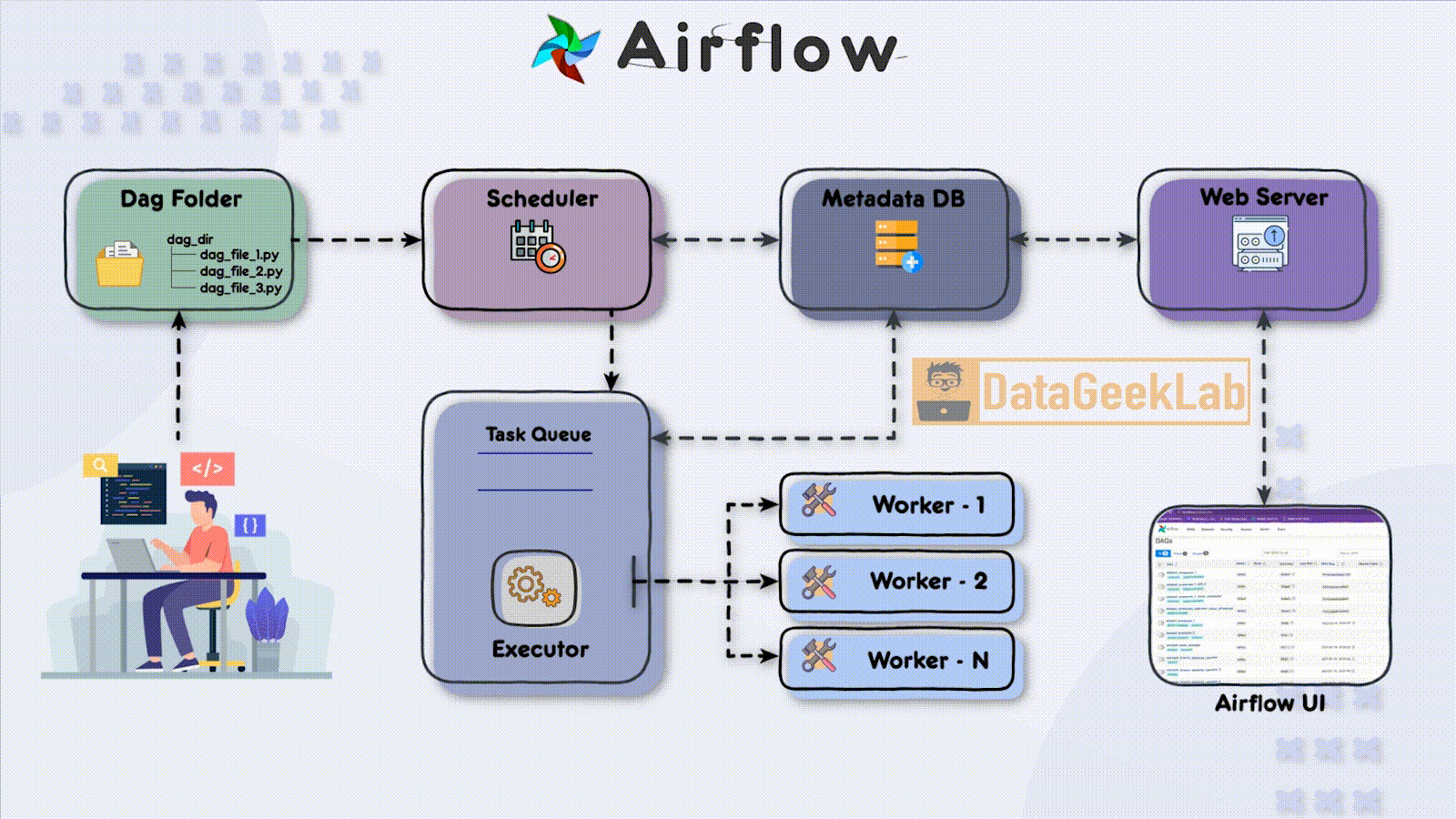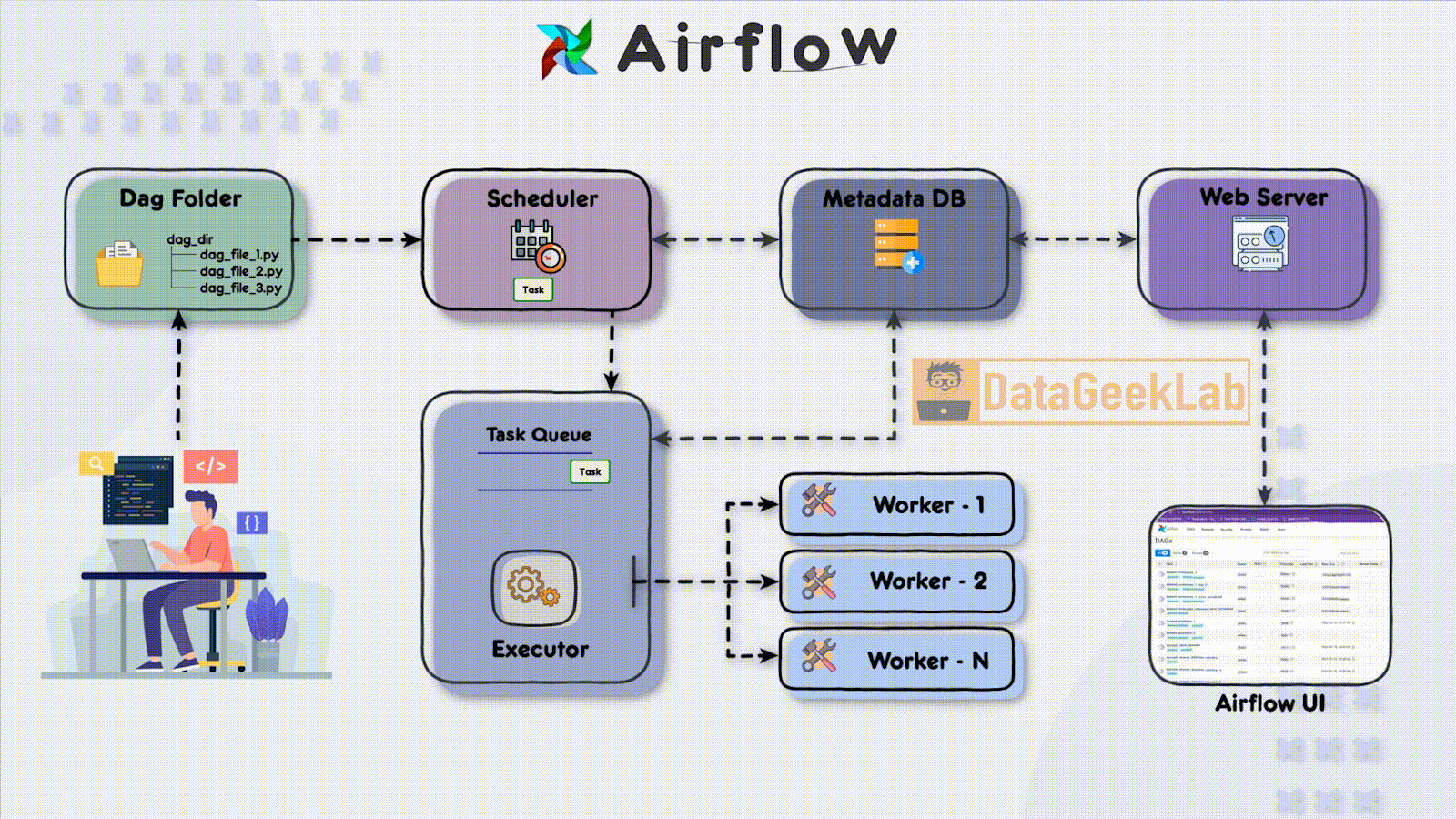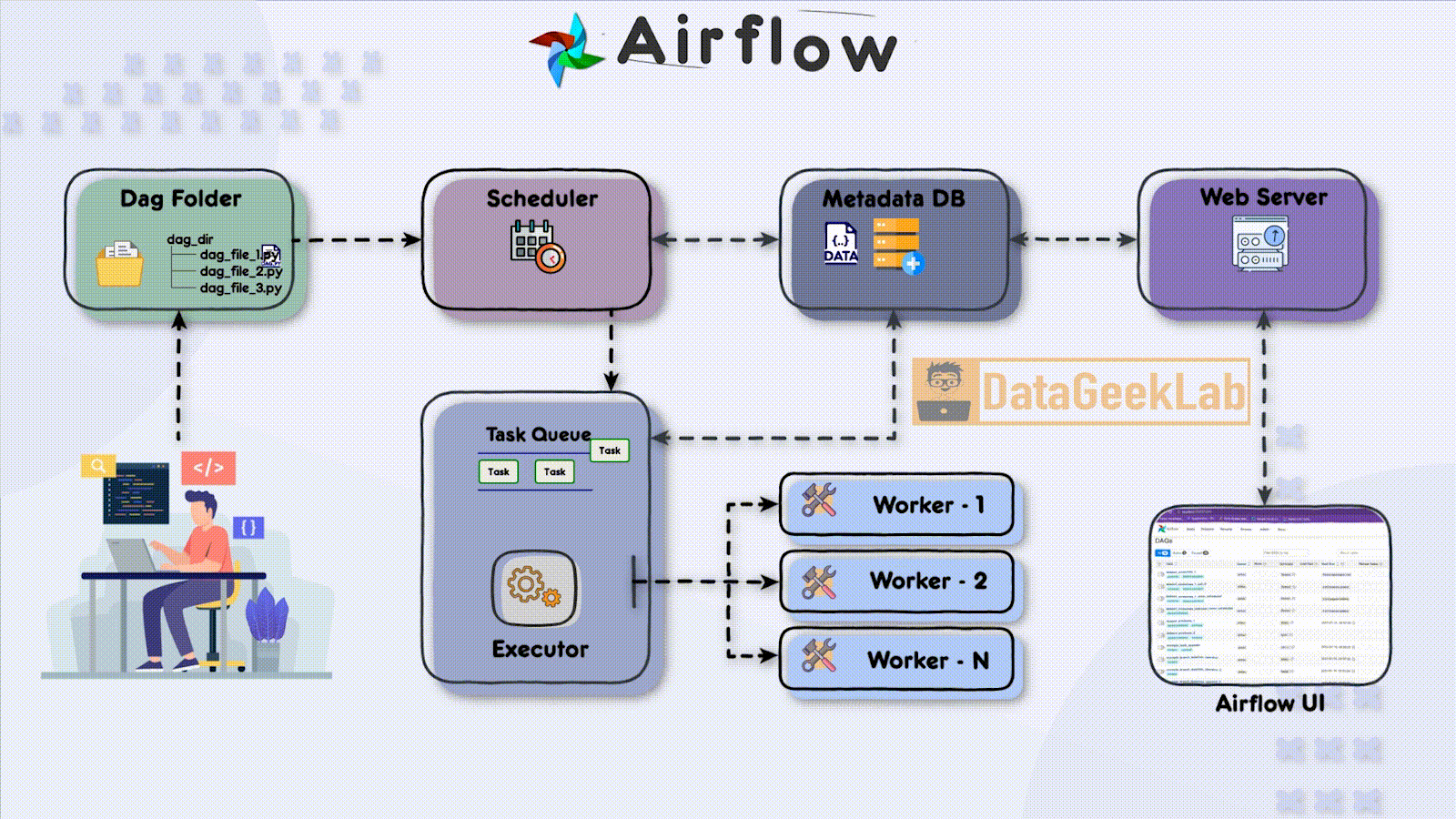
In Apache Airflow Architecture scheduler component plays a vital role in workflow execution. It periodically scans the DAG folder, detecting any new or updated DAG files. Upon detection, the scheduler creates task instances based on the definitions within the DAG files. These task instances represent individual units of work that need to be executed.
To ensure the orderly execution of tasks, the scheduler places the task instances in a task queue. The task queue acts as a buffer between the scheduler and the executors, ensuring that tasks are executed in the specified order and allowing for distribution among available workers. The task queue serves as a mechanism for load balancing and parallel task execution.As stated in this article, you can browse your selection of available deals on smartphones and top brands and explore the cell phone service plans that best suit your needs.
Section 3: Executors and Workers
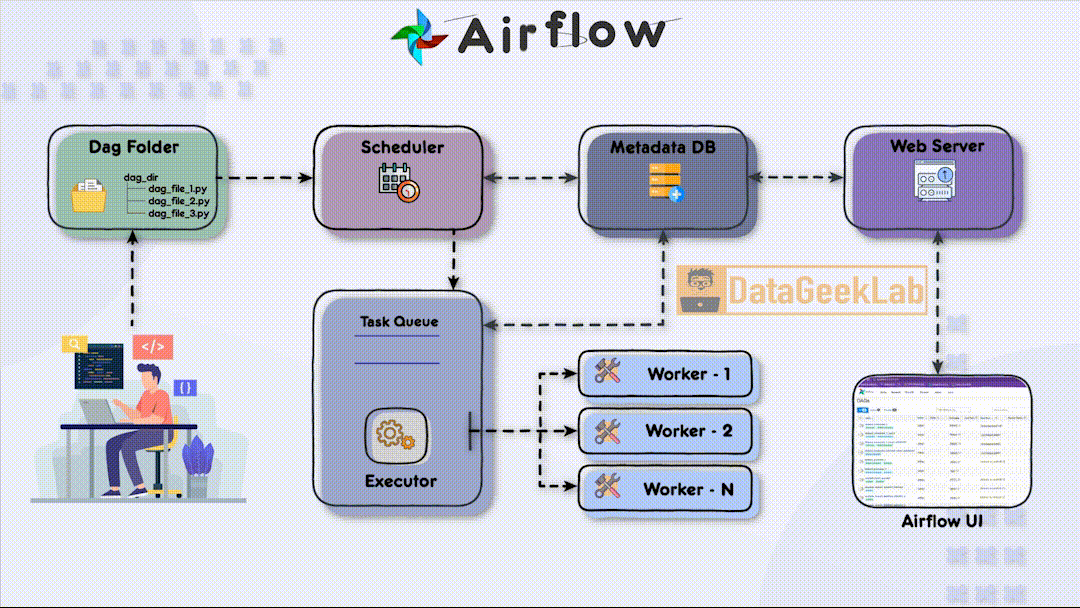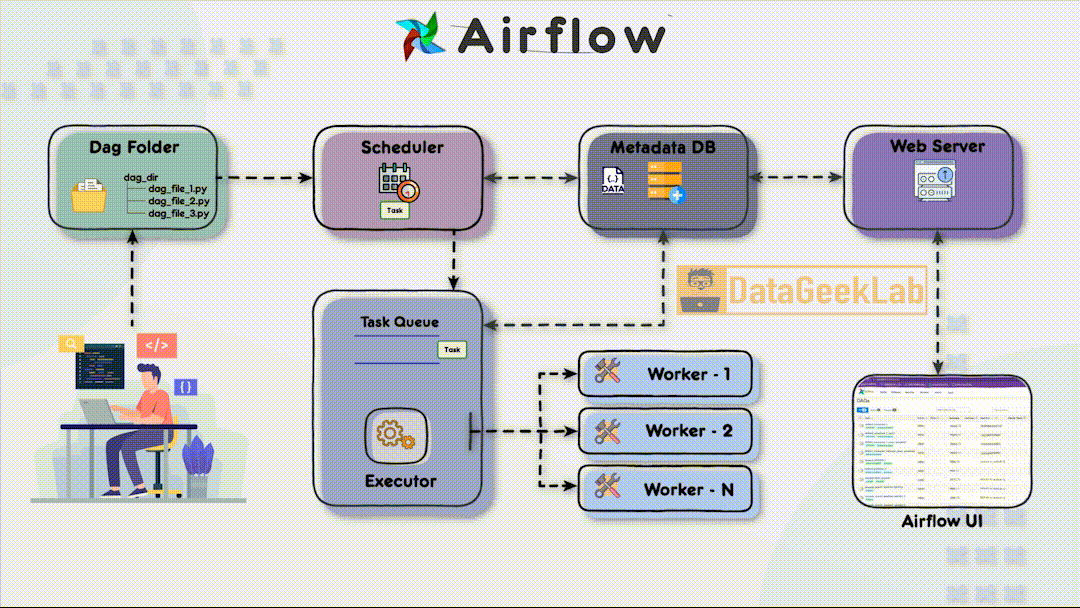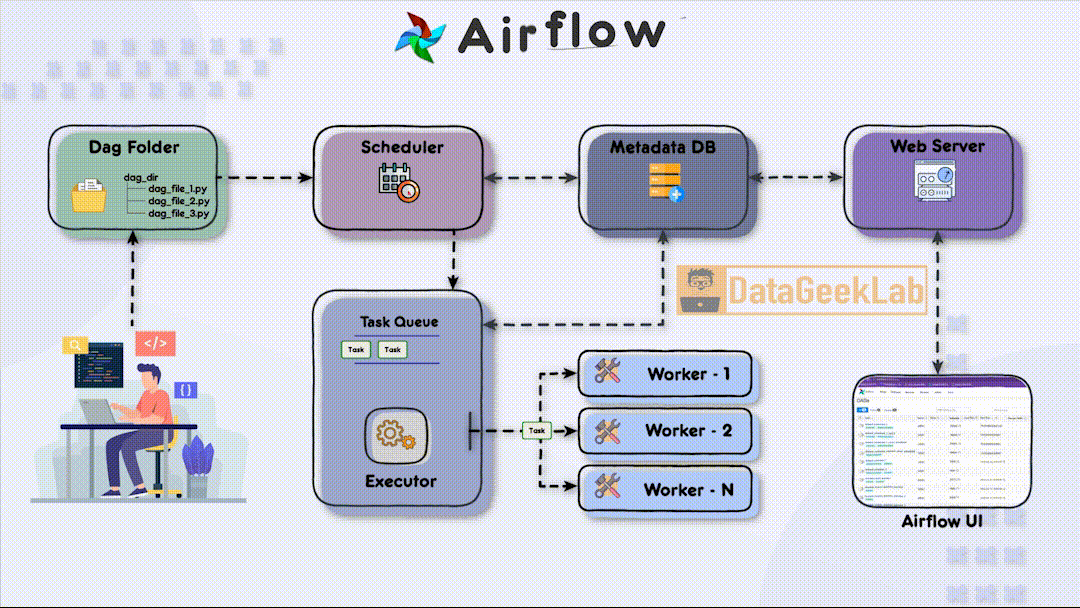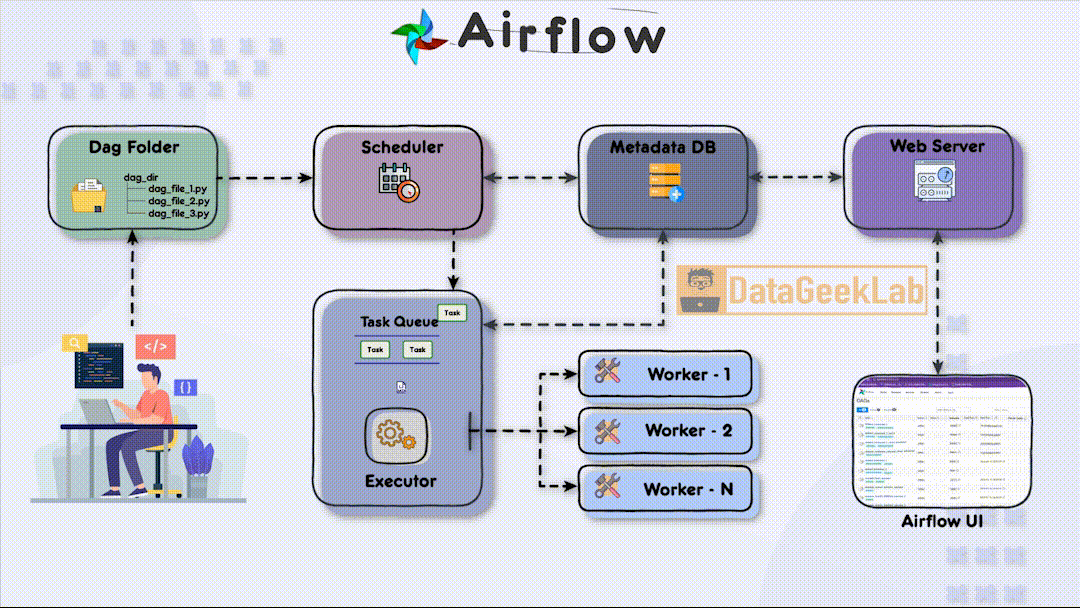
Airflow supports different executor types, each determining how tasks are executed in your Apache Airflow Architecture. The SequentialExecutor is a basic executor that runs tasks sequentially, making it suitable for development and testing purposes. On the other hand, the CeleryExecutor is widely used for distributed task execution. It leverages Celery, a distributed task queue system, to distribute tasks among multiple workers and achieve parallelism.
Within the executor, workers play a crucial role in executing the assigned tasks. Each worker operates in a separate process or container and can run multiple tasks concurrently, depending on the configuration. Workers retrieve tasks from the task queue and execute them, making efficient use of available computing resources and speeding up workflow execution.
Section 4: Metadata Database and Task Monitoring
In Apache Airflow Architecture during task execution, both the scheduler and the executor update a metadata database. This database stores essential information about task status, execution history, task dependencies, and more. Airflow supports various metadata databases, including popular options like PostgreSQL and Apache Cassandra. The metadata database enables developers and users to monitor workflow progress, troubleshoot issues, and gain insights into task execution.
Section 5: Web Server and User Interface
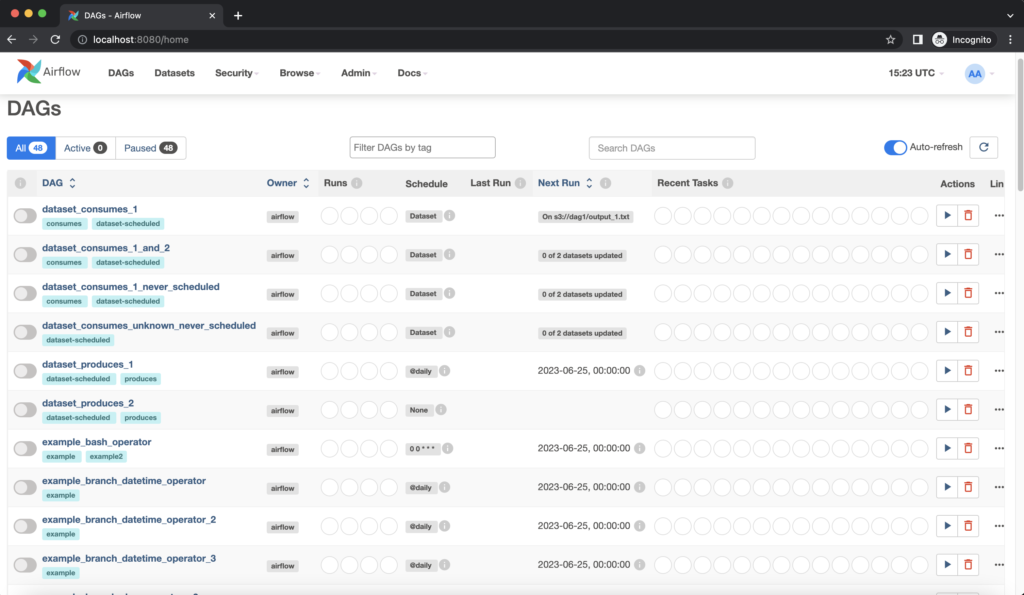
Finally Apache Airflow Architecture has a web server component that hosts a user-friendly interface (UI) for monitoring and managing workflows. The web server interacts with the metadata database, retrieving information about task statuses, logs, and execution history. The UI presents this data in a comprehensive and accessible manner, allowing developers and users to monitor the status of their workflows, inspect task details, and troubleshoot any issues that may arise.
Section 6: Developer Interaction and Workflow Management
Through the Airflow UI, developers have direct access to monitor the progress and status of their DAGs. They can check detailed task execution information, view logs, and make necessary adjustments to the workflow. The UI provides a centralized platform for developers to manage their workflows efficiently and ensure smooth data pipeline operations.
Conclusion – Apache Airflow Architecture
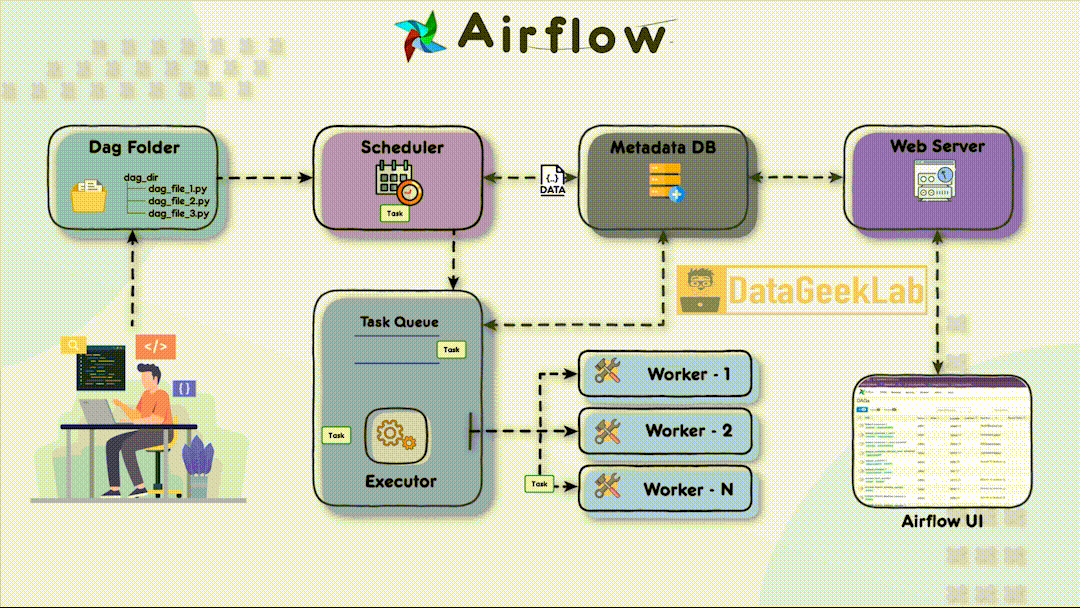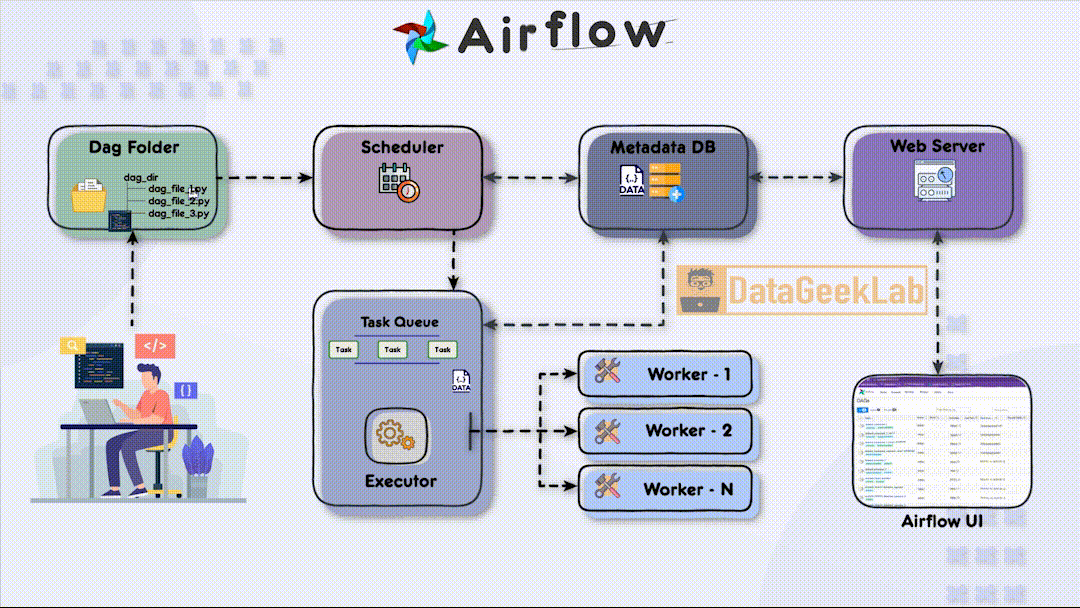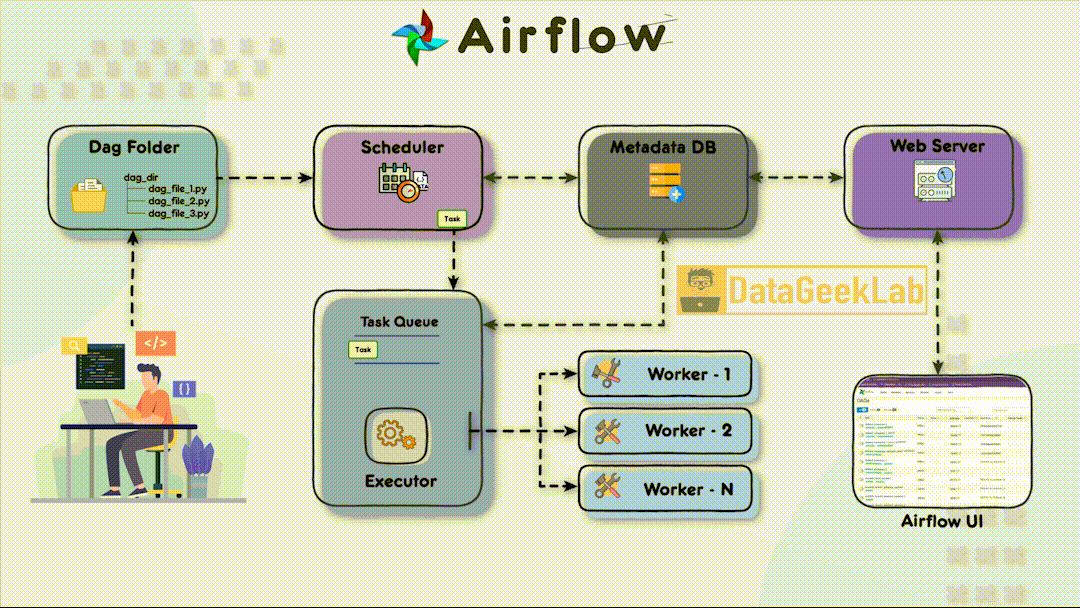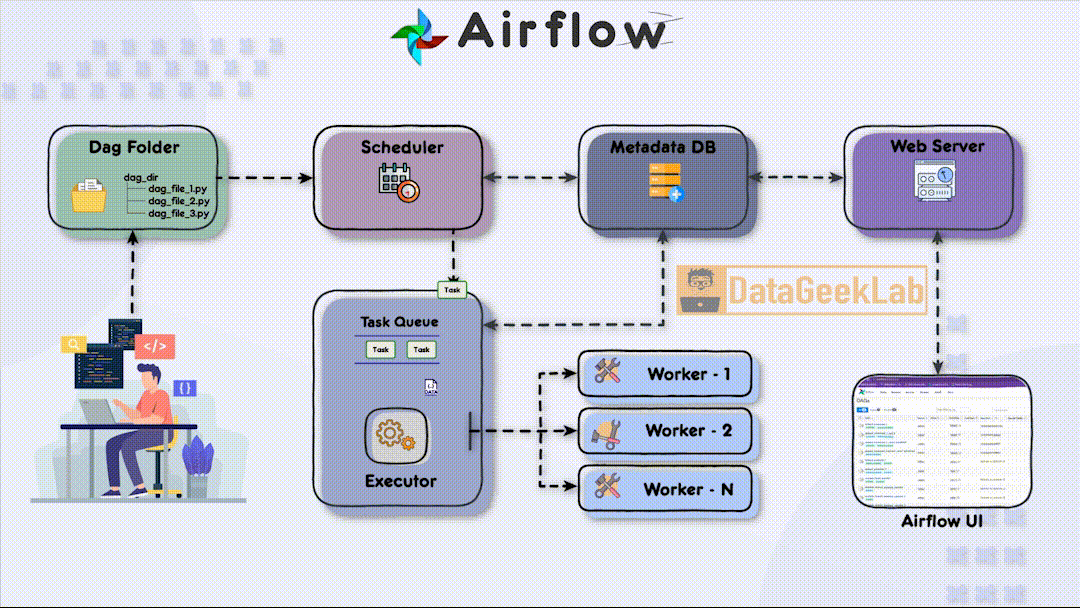
In Apache Airflow Architecture different components work in harmony to streamline data workflows, offering data engineers a robust platform for managing and automating complex tasks. With Airflow, organisations can achieve improved efficiency, scalability, and reliability in their data processing pipelines. By understanding the various components and their functionalities, data engineers can harness the full potential of Airflow to drive productivity and make data-driven decisions.
If you’re interested in learning more about data processing, check out some of our other articles here
3 thoughts on “Ultimate Apache Airflow Architecture: 7 Key Components Revealed”