
I’ve spent the last eight years knee-deep in data on Google Cloud, and if there’s one conversation that has completely reshaped how we build data platforms, it’s the ETL vs ELT debate. A decade ago, this wasn’t even a question. Today, it’s the fundamental choice that dictates the speed, flexibility, and cost of your entire data strategy.
Why is this more relevant than ever in 2025? Because of the sheer power of cloud-native data warehouses like GCP BigQuery and Snowflake. These platforms didn’t just give us more storage; they fundamentally changed the economics of data processing. They made it possible to ask: “What if we stop doing all the heavy lifting upfront?”
If you’re building a data pipeline today, you’re standing at this crossroads. Choosing the right path is one of the most critical data engineering best practices. In this guide, I’ll break down the difference between ETL and ELT from a practical, in-the-trenches perspective—no fluff, just lessons learned from building and scaling real-world systems.

What is ETL? The Classic, Battle-Tested Approach
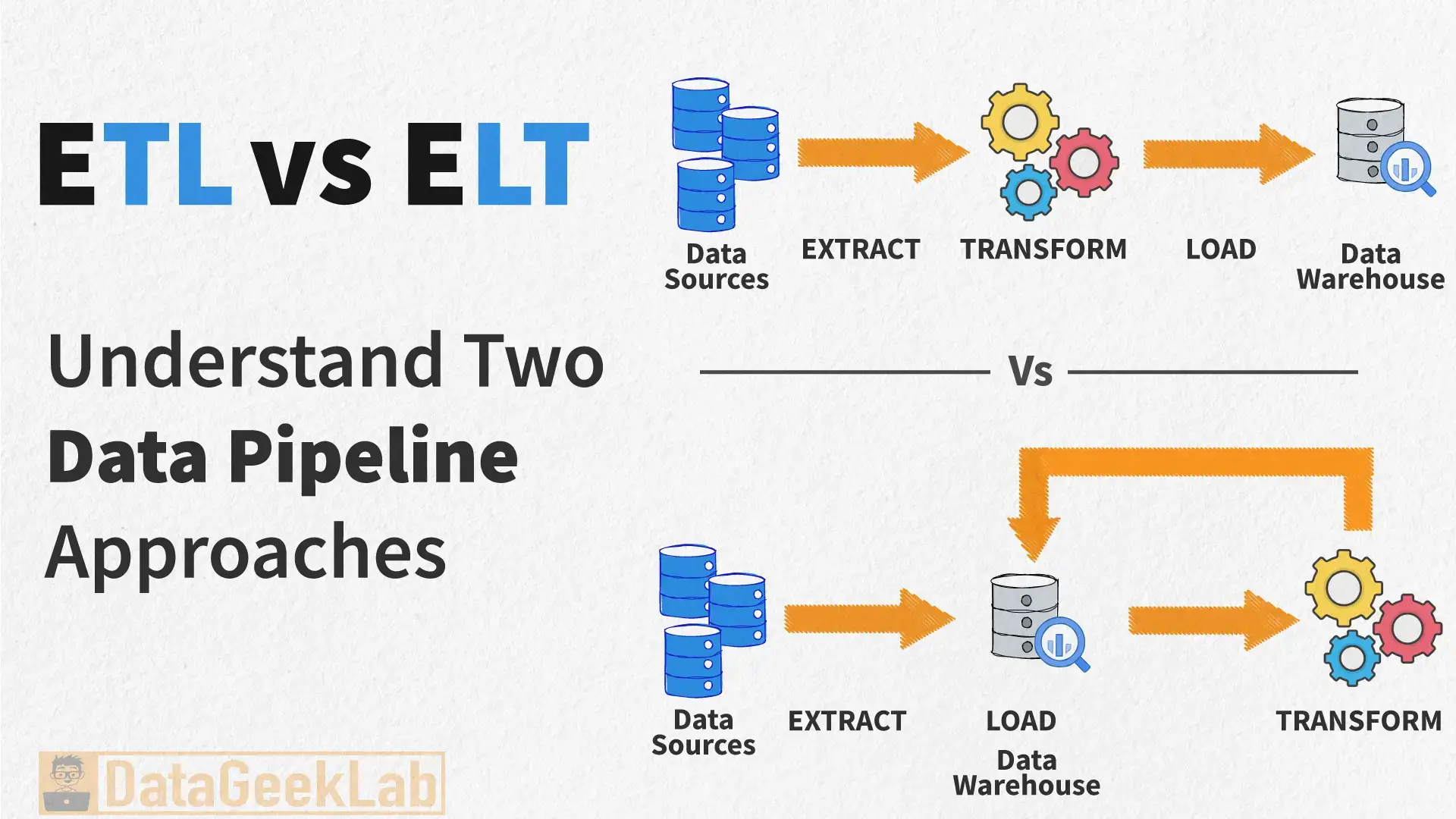
ETL stands for Extract, Transform, Load. This was the gold standard for decades, and for good reason. It’s a structured, disciplined approach to data integration.
Think of it like buying finished furniture from a large factory. The factory (a dedicated transformation server) takes raw lumber (data), and their specialized, heavy machinery cuts, sands, and assembles it (transforms it) into a specific piece, like a bookshelf. Only that final, polished bookshelf is shipped to your home (the data warehouse). The process is rigid; you can’t easily turn that bookshelf into a chair once it arrives.

How ETL Works
- Extract: You pull data from your sources (e.g., a production database, a CRM like Salesforce).
- Transform: This is the key step. The raw data is moved to a separate processing engine or staging area. Here, you apply business logic, clean the data, perform calculations, and join datasets. This requires a powerful, often expensive, server because it’s doing all the computational work.
- Load: The final, polished, and structured data is loaded into the target data warehouse. The raw data is typically discarded.
A Practical ETL Example: E-Commerce Sales
Let’s say we have raw sales data from a production database. Our goal is to create a daily sales report.
Source Data:
transaction_id | user_id | amount_cents | product_sku | timestamp_utc |
101 | 987 | 5000 | ABC-123 | 2025-10-11 12:30:00 |
102 | 123 | 7550 | XYZ-789 | 2025-10-11 12:32:15 |
In an ETL workflow, the process is:
1. Extract: A script pulls these rows from the source database.
2. Transform: The data is processed by a Cloud Dataflow job. This job runs a pipeline using Python and Apache Beam to perform the transformation in memory.
Sample Dataflow Python Code (Simplified):
import apache_beam as beam
def calculate_sales(element):
# element is a dictionary like {'amount_cents': 5000, 'product_sku': 'ABC-123', ...}
return (element['product_sku'], element['amount_cents'] / 100.0)
with beam.Pipeline() as pipeline:
transformed_data = (
pipeline
| 'ReadData' >> beam.io.ReadFromSource(...)
| 'CalculateDollars' >> beam.Map(calculate_sales) # Output: ('ABC-123', 50.0)
| 'GroupByProduct' >> beam.GroupByKey()
# Output: ('ABC-123', [50.0, ...])
| 'SumSales' >> beam.Map(lambda (key, values): {'product_sku': key, 'total_sales': sum(values)})
# Output: {'product_sku': 'ABC-123', 'total_sales': 50.0}
| 'WriteToBigQuery' >> beam.io.WriteToBigQuery(...)
)This code reads the raw data, calculates the dollar amount, groups all sales by the product SKU, and sums them up before writing the final, aggregated result to BigQuery.
3. Load: The final, transformed data is loaded into BigQuery. The raw data is discarded.

Data Loaded into BigQuery:
sale_date | product_sku | total_sales_dollars |
2025-10-11 | ABC-123 | 50.00 |
2025-10-11 | XYZ-789 | 75.50 |
The problem remains: we’ve lost the raw details. If someone asks for sales by user_id or the number of transactions, we can’t answer. The transformation was pre-defined and inflexible.
Where ETL Still Wins
I’m a huge advocate for modern approaches, but ETL isn’t dead. It’s still the right choice for specific scenarios:
- Data Privacy and Compliance: When you need to scrub, hash, or anonymize sensitive PII data before it ever lands in your warehouse, ETL is the only way to guarantee it.
- Legacy Systems: Many older data warehouses were not powerful enough to handle transformations, making ETL a necessity.
- Complex, Non-SQL Transformations: If your logic involves complex procedural code or machine learning models that are easier to implement in Python or Java, doing it in a tool like Dataflow (ETL) makes sense.
What is ELT? The Modern, Cloud-Native Paradigm
ELT flips the script: Extract, Load, Transform. This approach is the backbone of the modern data stack and is tailor-made for the power of cloud data warehouses.
This is like getting raw lumber delivered to your own high-tech workshop. You load all the raw lumber (data) directly into your workshop (the data warehouse). Your workshop is equipped with incredibly powerful, automated tools (the GCP BigQuery engine) that can cut and shape the wood into anything you want, whenever you want. Today you can make a bookshelf. Tomorrow, using the same raw lumber, you can make a chair. The process is flexible because the transformation happens in your powerful workshop.

How ELT Works
1. Extract: You pull raw data from your sources.
2. Load: You immediately load that raw, unchanged data directly into your cloud data warehouse like GCP BigQuery. Storage is cheap, so you keep everything.
3. Transform: The magic happens here. You leverage the immense parallel processing power of the warehouse itself to run transformations using SQL. Tools like dbt (data build tool) have become the standard for managing these in-warehouse SQL transformations.
A Practical ELT Example: E-Commerce Sales with BigQuery
Using the same e-commerce data, the ELT approach is fundamentally different:
1. Extract: A script pulls the raw rows from the source database.
2. Load: The script immediately loads the raw, unchanged data into a BigQuery table, let’s call it sales_raw_data.
Data Loaded into BigQuery (sales_raw_data table):
transaction_id | | amount_cents | product_sku | timestamp_utc |
101 | 987 | 5000 | ABC-123 | 2025-10-11 12:30:00 |
102 | 123 | 7550 | XYZ-789 | 2025-10-11 12:32:15 |
3. Transform: Now, we run a SQL query inside BigQuery to produce our final, aggregated table. This is where the power of BigQuery’s engine is used.
BigQuery SQL for Transformation:
-- This query runs directly in BigQuery
CREATE OR REPLACE TABLE my_dataset.daily_sales_report AS
SELECT
DATE(timestamp_utc) AS sale_date,
product_sku,
SUM(amount_cents / 100.0) AS total_sales_dollars
FROM
my_dataset.sales_raw_data
GROUP BY
1, 2;Final Output (daily_sales_report table):
sale_date | product_sku | total_sales_dollars |
2025-10-11 | ABC-123 | 50.00 |
2025-10-11 | XYZ-789 | 75.50 |

The advantage is immense. All the raw data is still in the sales_raw_data table.
Let’s say the business team comes back with a new request: “Can we see the total spending and number of transactions for each user?”
In the ETL world, this would be a disaster. We threw away the user_id and individual transaction details during the initial transformation! We’d have to ask an engineer to redesign the entire pipeline, which could take days or weeks.
With ELT, it’s just another query. We run a new transformation on the same raw data we already loaded:
New BigQuery Query for User-Level Sales:
-- A new query on the SAME raw data to answer a NEW question
CREATE OR REPLACE TABLE my_dataset.daily_sales_by_user AS
SELECT
DATE(timestamp_utc) AS sale_date,
user_id,
COUNT(transaction_id) AS number_of_transactions,
SUM(amount_cents / 100.0) AS total_spent
FROM
my_dataset.sales_raw_data
GROUP BY
1, 2;Resulting daily_sales_by_user table:
sale_date | user_id | number_of_transactions | total_spent |
2025-10-11 | 987 | 1 | 50.00 |
2025-10-11 | 123 | 1 | 75.50 |
This is the core value of ELT: unmatched flexibility. You can answer questions you didn’t even know you had when you designed the pipeline.
Why ELT Dominates the Cloud
From my experience, the shift to ETL vs ELT was driven by one thing: the architecture of cloud data warehouses.
- Separation of Storage and Compute: This is BigQuery’s superpower. You can store petabytes of raw data for a very low cost. When you need to transform it, BigQuery unleashes thousands of CPUs to process your query in seconds, and you only pay for that brief execution time. You’re no longer paying for an expensive, always-on transformation server.
- Raw Data is Gold: With ELT, you never throw away the raw data. If your business asks a new question tomorrow, you don’t have to rebuild your entire pipeline. You just write a new SQL model on the raw data you already have. This provides incredible agility.
- Empowering Analysts: It democratizes data transformation. Analysts who are proficient in SQL can now build their own data models and reports without waiting for an engineer to modify a complex ETL script.
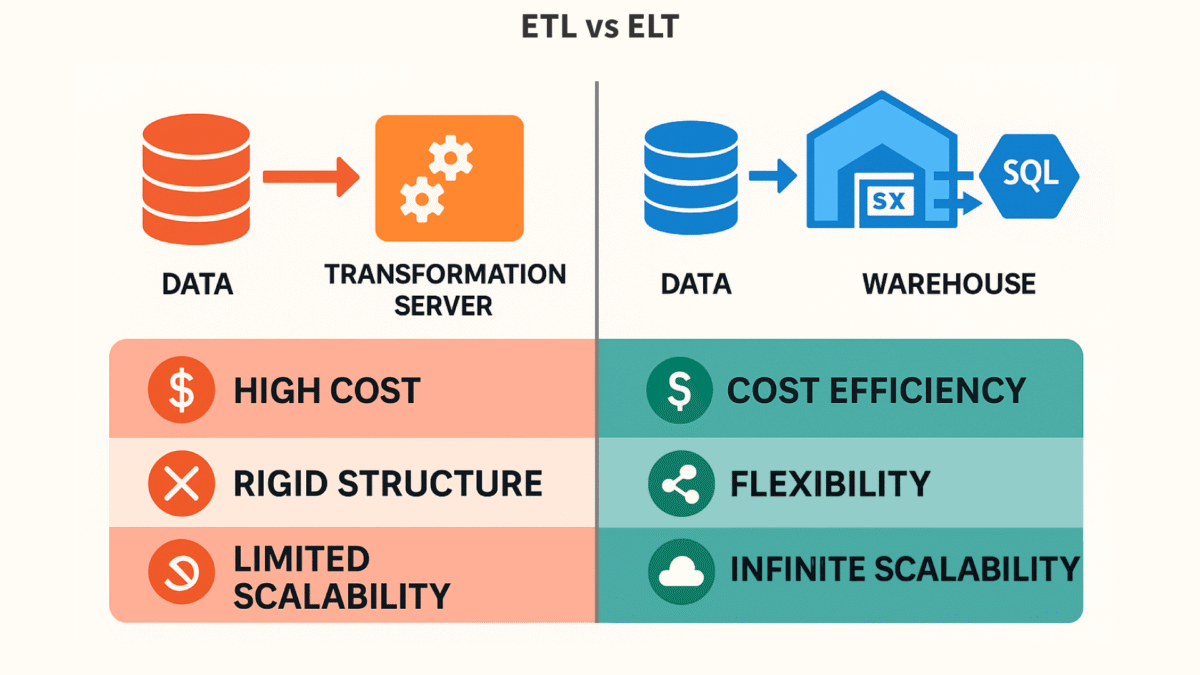
Key Differences: ETL vs ELT Side-by-Side
Here’s a quick cheat sheet I use when explaining the difference between ETL and ELT to stakeholders.
| Feature | ETL (Traditional) | ELT (Modern) |
|---|---|---|
| Primary Order | Extract → Transform → Load | Extract → Load → Transform |
| Transformation Engine | Dedicated staging server (e.g., Informatica, SSIS, custom scripts) | Inside the target data warehouse (e.g., BigQuery, Snowflake) |
| Data in Warehouse | Cleaned, structured, and aggregated data only. | All raw data is loaded first, then transformed into new tables. |
| Scalability | Limited by the transformation server’s capacity. | Nearly infinite, leveraging the cloud warehouse’s scale. |
| Flexibility | Rigid. Schema-on-write. Changes are slow. | Highly flexible. Schema-on-read. Adapt to new needs quickly. |
| Cost Model | High upfront/fixed cost for transformation servers. | Pay-per-query model. Cheaper storage, variable compute. |
| Maintenance | High. Maintaining a separate transformation server. | Low. The warehouse provider manages the compute infrastructure. |
| Data Availability | Limited to pre-defined transformations. | Full raw dataset available for ad-hoc exploration and re-modeling. |
| GCP Tools | Cloud Dataflow, Cloud Data Fusion, Dataproc | Cloud Functions/Storage + BigQuery + dbt/Dataform |
When to Use ETL vs ELT: An Engineer’s Decision Guide
Choosing between ETL vs ELT is a critical design decision. Here’s my mental checklist:
Choose ETL when:
- You have strict data privacy requirements. If you absolutely cannot let raw PII land in your warehouse, even temporarily, you must transform it first.
- You are working with legacy systems. If your target warehouse isn’t powerful enough to handle transformations, ETL is your only option.
- Your transformations are computationally heavy and not SQL-friendly. Think complex simulations or procedural data cleansing that’s easier to write in Python or Java on a dedicated compute cluster.
Choose ELT when (90% of my projects today):
- You are using a modern cloud data warehouse like GCP BigQuery, Snowflake, or Redshift.
- You need speed and flexibility. Business requirements are changing, and you want to enable your analytics team to be self-sufficient.
- You are dealing with large volumes of data. It’s often faster to load data in bulk and let the warehouse’s parallel engine handle the transformation.
- Your data sources are numerous and varied. It’s simpler to create a standardized loading process for all raw data and then harmonize it within the warehouse.
Actionable Advice: Evaluate your current data workflow. Are your analysts constantly waiting for engineering to make small changes to a pipeline? That's a strong signal it's time to switch to ELT.
ELT and ETL in Practice on Google Cloud (GCP)
On GCP, you’re not forced to choose just one. We often build hybrid solutions. Here’s how the tools map out:
- For Extraction and Loading (the “EL”):
- Cloud Dataflow/Apache Beam: Excellent for large-scale, reliable data movement from various sources.
- Cloud Functions: Perfect for lightweight, event-driven data ingestion (e.g., a new file lands in GCS).
- Third-Party Tools: Services like Fivetran and Airbyte are fantastic for connecting to hundreds of SaaS APIs with pre-built connectors.
- Cloud Dataflow/Apache Beam: Excellent for large-scale, reliable data movement from various sources.
- For Transformation (the “T”):
- BigQuery (for ELT): This is your primary transformation engine. You write SQL queries, and BigQuery executes them at scale.
- dbt/Dataform (for ELT): These tools are essential for managing, testing, and documenting your SQL transformations within BigQuery.
- Dataflow (for ETL): When you need to do pre-load transformations, Dataflow is the go-to managed service.
- Dataproc (for ETL): If you have a massive Spark-based transformation job, you can run it on a managed Dataproc cluster.
- BigQuery (for ELT): This is your primary transformation engine. You write SQL queries, and BigQuery executes them at scale.

A lesson from experience: My team’s biggest productivity gain came when we stopped using Dataflow for complex business logic. We simplified our Dataflow jobs to just load raw data, then moved all the transformation logic into dbt models running on BigQuery. Our development cycle went from days to hours.
Future Trends: What’s Next for Data Integration?
The ETL vs ELT story is still evolving. Here’s what I see coming in 2025 and beyond:
- The Rise of “ETLT”: A hybrid model is becoming common. You perform light, essential transformations upfront (ETL-style), like anonymizing PII, and then do the bulk of the business logic and aggregation in the warehouse (ELT-style).
- Streaming ELT: With tools like BigQuery’s streaming inserts and Materialized Views, we’re moving towards near-real-time ELT. Data is loaded second-by-second, and transformations are run continuously on these micro-batches.
- Reverse ETL: This is the new frontier. Once you have clean, transformed data in your warehouse, Reverse ETL tools push that data back out to operational systems like Salesforce or Marketo, ensuring all your business tools are running on the same trusted data.

Conclusion: It’s Not Just a Choice, It’s a Strategy
For years, the ETL vs ELT debate has been framed as a technical choice. It’s not. It’s a strategic one. Choosing ETL optimizes for structured, predictable reporting. Choosing ELT optimizes for speed, flexibility, and discovery.
As a modern data engineer, your job is to be adaptable. While ELT is the dominant paradigm in the cloud, the best engineers I know understand both patterns deeply and know precisely when to apply each one. The goal isn’t to be an “ETL engineer” or an “ELT engineer,” but to be a data engineer who delivers value.
The tools will continue to change, but the principles of efficient data integration remain. By mastering both approaches, you’re not just following data engineering best practices—you’re future-proofing your career.
Ready to get started? Begin building your modern data pipeline today. Pick a dataset, load it raw into BigQuery, and start transforming. There's no substitute for hands-on experience.
Frequently Asked Questions (FAQs)
1. Which is better — ELT or ETL?
Neither is universally “better,” but ELT is generally preferred for modern, cloud-based data warehousing. It offers more flexibility, scalability, and is more cost-effective for large datasets. ETL is better for specific use cases like pre-load data anonymization or when using legacy systems.
2. Why is ELT more popular in cloud environments?
Because cloud data warehouses like GCP BigQuery are built with a decoupled storage and compute architecture. This makes it incredibly cheap to store raw data and extremely powerful to transform it on-demand. ELT leverages this architecture perfectly, while the ETL model was designed for on-premise systems where compute was a fixed, expensive resource.
3. Can you use both ETL and ELT in the same data pipeline?
Yes, absolutely. This is called a hybrid or “ETLT” approach. A common pattern is to use an ETL step to perform initial data cleansing or PII anonymization before loading the data into the warehouse. Then, the rest of the complex business logic and aggregations are handled with an ELT approach inside the warehouse.
4. Is dbt an ETL or ELT tool?
dbt is the “T” in ELT. It doesn’t do extraction or loading. It is specifically designed to manage the transformation step after data has already been loaded into a data warehouse. It has become the industry standard for this part of the ELT process.
5. Does ELT replace the need for data engineers?
No, it changes the role of a data engineer. Instead of writing complex transformation scripts, engineers now focus on building robust and scalable data loading systems, managing the transformation framework (like dbt), optimizing warehouse performance and cost, and ensuring data quality and governance. The focus shifts from procedural coding to SQL-based modeling and platform management.
If you are interested in other Data Engineering topics check out some of my other articles on Airflow Architecture, What Data Engineers Do ? , Table Partitioning etc. You can also checkout the official GCP website to learn tools like BigQuery, Dataflow etc